
…or optimize anything you can vary and measure.
I recently got very excited when I discovered that there was a massive amount of freely available health/wellness knowledge at YouTube. I have binge-watched almost all there is in 2x speed over several months, and then it suddenly started creeping in: Can I trust the info? Are the interviewees just repeating what others consider to be the truth? Is the knowledge directly transferrable to me? So you might ask – what is the right approach? Should we just listen to the advice we get from our governments, the fitness influencers and gurus, findings in various studies (your body≈average mouse) or broscience from friends? That is what usually is done, but we can actually do so much better!
The body is extremely complex. If we were able to control every aspect of our lives, e.g. food, sleep, exercise, stressors etc. (inputs), and we knew how they would affect the outcomes, e.g. fat loss, muscle gain, central nervous system (outputs), you would think that everyone could have perfect health and perfect Barbie and Ken bodies.
That is sort of true, but the problem is that we will never know all the inputs that have an influence on the outputs, the inputs can also be outputs (e.g. sleep), the intputs can contribute in combination (exercise and diet both influence body composition) and the model that describes these relationships between inputs and outputs will be individual for each person.
Bruce Lee tactics
So first a disclaimer: I am not a medical professional, but rather by profession an engineer working with optimization problems at times. I have just scratched the surface of how medical studies are conducted by peeking into interesting studies in PubMed from time to time, but usually just understand parts of the study content and can barely understand the results. The methods and results that are following are sort of a legit engineering approach to better understand something that is complex and difficult to understand (the body) by using the shortest possible route.
The methods used are under the umbrella topic Design of Experiments (DoE), but is just the first step, known as a screening design, where the goal is to find the relevant factors and discard the irrelevant ones (Bruce Lee tactics).
The absolute greatest influence I have had for this comes from attending the MOOC Coursera Course “Experimentation for Improvement” taught by former assistant professor Kevin Dunn at McMaster University. I was sad to hear that he has, since attending the course the last time, moved to Europe and is not teaching at the moment.

The reason it is sad is that he is a fabulous and, in my opinion, under-appreciated teacher, the course is excellent and he has many freely available resources, including R-scripts for free data analysis and a complete and throrough book (yes book) about “Process Improvement Using Data”, where you can find much more in depth details of DoE in chapter 5.
It is important to point out that the course is still available, being revised since first started in 2015(?). This is timeless know-how so I would highly recommend everyone interested in (self)improvement to attend. Trust me: Kevin is making everything very easy to understand.
I would also have to mention that the results further shown in this article are over one year old (started end of August 2020 and lasted two months). I originally figured it would be a good idea to put the content into a YouTube-video, but got scared and wrote this article one year later instead. Every bit of DoE yellowbelt-know-how was fresh back then, and I probably have forgotten half of the important things.
The crux of DoE (screening designs)
Street wisdom in the recent years is that you can create a model for just about everything, you just need to get lots of data and throw the data into a deep learning model and you get a perfect fit. That is all good if you have all the data in the world, have a supercomputer to calculate the model and don’t want to learn how the model is working. I’m leaning more towards models that are very simple (parsimoneous), require the minimum amount of data (I call it “Small Data™“) and give you maximum insight to the model (white box model). DoE screening designs fullfill all this.
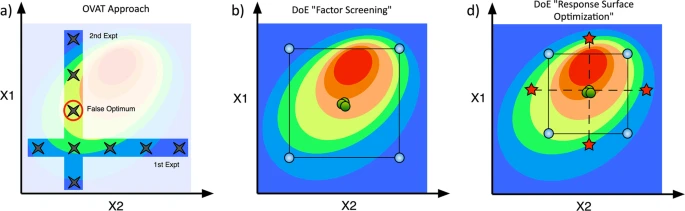
You were taught in school that you vary one thing at a time and then check the outcome (i.e. A/B testing). Then you vary another thing and recheck the outcome. You would think that the former best will be the best starting point when changing other things as well. Correct? Wrong!! At least in many cases you can falsely believe that you get the best end result by combining the effects of each best result. An example from fat loss would be that you believe training HIIT every day is good, keto is also good, and so is intermittent fasting, resistance training and zone 2 training. If you combine the overall best from these 24-7 you will probably be highly stressed, overtrained and sick rather than fit and slim.
The Pareto Principle, also known as the 80/20 rule, is a very interesting principle that should be taught early on in life. The simplified self-help version is that 80% of the outcome is the results of applying effort on the 20% most important factors. I think I first got to know the principle through professor Alexander Slocum at MIT, through some of his recommended principles while working on engineering tasks, but it was later widely popularized through Tim Ferriss (yet another backlink), who applies this principle to most things in life and has made whole books and videos based on applying this principle to learning anything he is set to or interested in.
In my experiment I want to apply the Pareto Principle to exercise and diet to identify the most important factors that will make me fit (not sure what I want to obtain, but a slimmer and more muscular version of me would be a good start). I start by setting up an screening design experiment where the outcome would be Pareto plots identifying the most important factors I should focus on to obtain these goals. Equally important: The Pareto plots will tell me which factors I should remove.
Experiments are costly (time, effort, money). The shitty thing is that you put in a whole lot of effort and have to wait until the full experiment is finished before you can collect the result. You can shortcut this (less time, effort or money) if you are absolutely certain that two inputs is not dependent on each other, and also then you need to be very careful to set up the experiment correct through “generators” to avoid what is known as “confounding”.
Design of Experiments helps you set up your experiment in a systematic way so that all combination of factors are varied each time and the runs are randomized. The beauty of the set of tools is that irrellevant factors can be removed after the screening design and you can reuse and expand upon these results to optimize the mix of the relevant factors. I used a fractional factorial screening design and stopped after the screening phase in my particular health experiment further explained below.
Before starting the experiment you also have to make certain that you are able to measure the outcome in a good way and that these measurement could be done at regular intervals. So how do you know what should be measured? You don’t know because your future self will have a different interest than your current self. A good rule of thumb would be to (within reason) collect as meany relevant (and irrellevant) outcomes as possible when you first do an experiment. By doing this you can expand on what you learn from one experiment rather than setting up multiple experiments. You can also repeat the test to further improve on your model.
Other important things that come to my mind and is worth mentioning when setting up the experiment; These are mostly my understanding and not Kevin is necessarily mentioning:
- Stay within the same physics throughout the experiment. The example from Kevins course is that when trying to maximize the number of popcorn kernels being popped you want to stay with the limits of popcorn being popped and before they start to burn. The example for exercise would be to neither under- nor undertrain.
- Choose outcomes/results that are measurable. This might seem easier than it really is as not all metrics are good metrics, some metrics vary slower than the experiment pace or has bad accuracy and/or precision.
- Make sure that the measurement results are settling and are the true outcomes of the test period.

The experiment setup
When planning an experiment you are adviced to use the “trade-off table”, shown below. Kevin can tell you all about this matrix, but it basically helps you find the trade off between cost and the information you gain from the experiment. I initially wanted to study 7 different factors and I wanted the experiment to last for eight weeks/runs. I thus selected the 2III,7-4 design. I tried protect my most important factors A-C from confounding and put the least interesting in factor G.

The factors were as follows:
- A) 1x or 2x weekly 4×4 running intervals from NTNU CERG
- B) 3 x 20s flat out spin bike HIIT intervals 1x or 2x weekly, popularized by Michael Mosley
- C) Reddit recommended bodyweight routine (strength) 1x or 2x weekly
- D) Cold showers or regular showers daily
- E) Breakfast or 16-8 intermittent fasting
- F) No or 2 table spoons of apple cider vinegar (ACV) before each meal
- G) Kefir probiotic included in the workout protein shake or not.
Factor G was later removed/held constant which resulted in duplicated runs. The volumes might seem small, but remember that an important goal was to avoid over-training. And my starting fitness was ok, but not super.
The measured outcomes were as follows:
- Average sleep score from Sleep Cycle App
- Weekly stamina score from Polar Beat App
- Average weekly HRV from Elite HRV App
- Weight, fat, muscle and water percentage from generic body impedance weight. Percentage results were converted to absolute values (kg) to avoid compounding percentages.
- Single point body fat caliper skin fold measurement, 3 averages with “El-cheapo” plastic calipers.
The results – Pareto plots with comments
From the R-documentation of ParetoPlot-function: “Creates a plot that shows the model coefficients from the least squares model as bars. The absolute value of the coefficients are taken. The coefficient’s sign is represented by the bar colour: grey for negative and black for positive coefficients.”
Body weight was reduced by doing HIIT and strength training
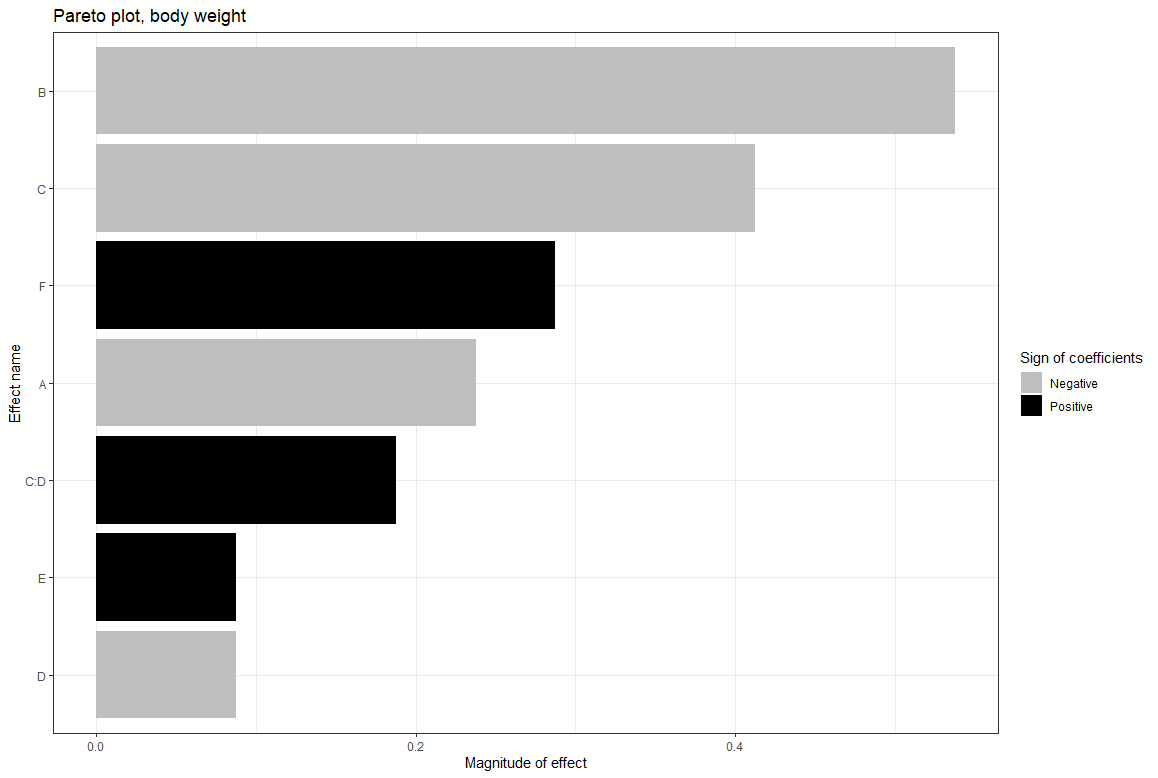
Body fat was reduced by doing HIIT and strength training

Muscle mass was negligibly reduced from HIIT and strength training

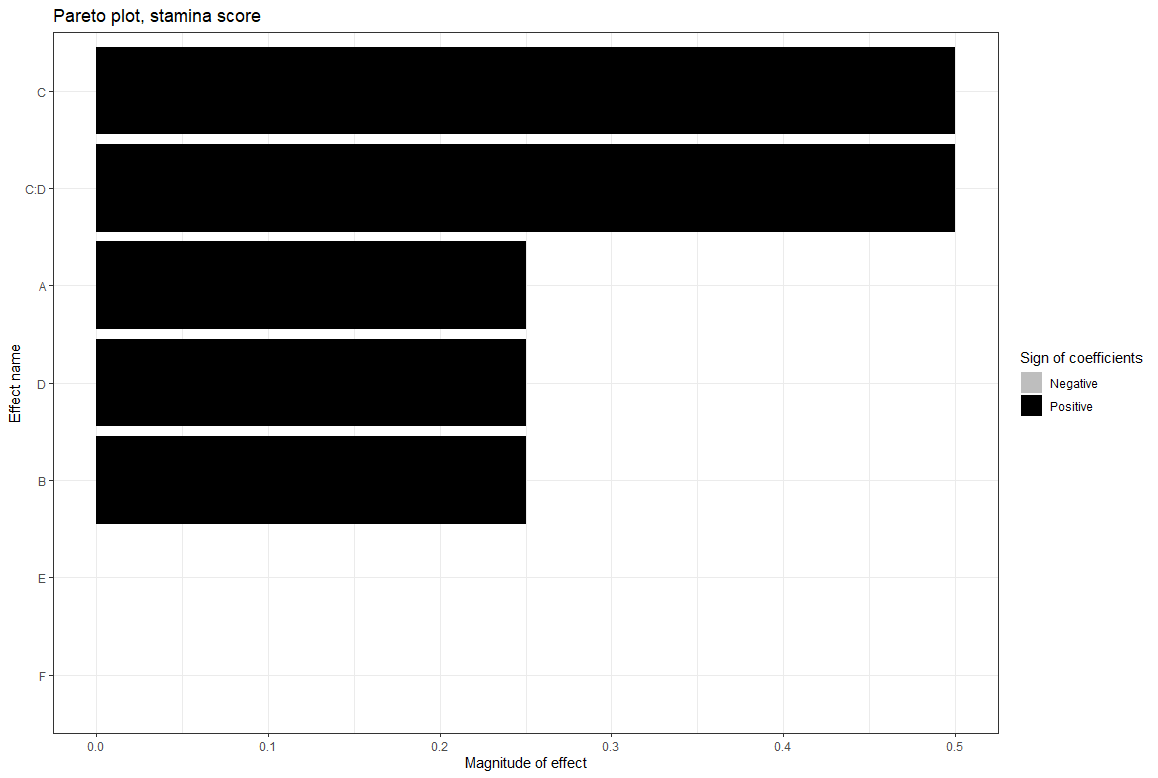
Sleep score was improved by doing HIIT and strength training

Stamina was neglibily improved by doing strength training
HRV was improved from strength training, but reduced from HIIT

Skin fold thickness (abdominal fat) was reduced by doing 4×4 intervals, but equally increased by doing 16-8 fast!

The conclusion
Even though my health-experiment was set up as meticulously as I could, it still had a lot of flaws:
- Each run lasted only one week. The effects of the combined factors had very limited time to make adaptive changes that were measurable. I did not have the patience or energy to set up an experiment for e.g. 4 months.
- Muscle and cardio stamina takes more than a week/one run to change and see significant results.
- Skin calipers are inaccurate over such a short time and done only for one body point.
- Body impedance weights are notoriously wrong and very much affected by hydration, when the measurements are done etc.
- The last two bullets should have been improved by using more accurate measurement instruments, like DEXA scans or hydro-weighing, none of which I have access to.
So the final conclusion is that the time period for the experiment and the measurements used are probably to coarse to draw any hard conclusions, but I will stick to especially 20s sprints/HIIT and strength training as a core of my health program.
I might come back with some scripts or step-by-step instructions, but I would rather recommend you take the course and then do your own experiment to figure out how to lose fat or gain muscle as fast as your (rather than my) body can.
